前言
在CatLua的开发结束后,出于对编译原理前端部分的学习兴趣,笔者便以一个适用于Unity的Json序列化库为目标进行开发
最终在较精简的源码基础上,完成了一个可以说是功能齐全,性能高效的Json序列化库CatJson
Runtime部分代码结构如下:
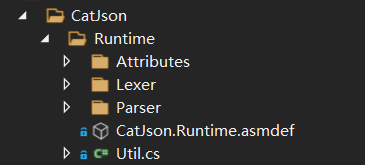
- Attributes:包含内置的特性标签,主要用于忽略字段和预生成转换代码
- Lexer:包含用于读取Json词法单元的Json词法分析器
- Parser:包含用于将Json文本与对象进行互相转换的Json解析器
词法分析
无论是要将Json文本转换为通用Json对象还是自定义数据对象,都需要能够先将Json的Token从字符串中一个接一个的提取出来,这就是Lexer所做的工作
CatJson中所使用的Lexer基本上与CatLua中的Lexer相同,具体可参看CatLua开发总结中的10.词法分析一节
与Lua不同的是,Json中的词法单元较少
TokenType枚举的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public enum TokenType
{
Eof,
Null,
True,
False,
Number,
String,
LeftBracket,
RightBracket,
LeftBrace,
RightBrace,
Colon,
Comma,
}
|
通用解析流程
在整个Json文本解析中,主要解析3类东西:
- Json键值对
- Json对象
- Json数组
而其中Json对象和Json数组的解析,对于将Json文本转换为通用Json对象和自定义数据对象来说具有相同流程,所以需要抽象出两个方法来统一这两个流程
解析Json对象的流程
解析Json对象的通用流程方法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public static void ParseJsonObjectProcedure(object userdata1,object userdata2,bool isIntKey,Action<object,object,bool,RangeString, TokenType> action)
{
Lexer.GetNextTokenByType(TokenType.LeftBrace);
while (Lexer.LookNextTokenType() != TokenType.RightBrace)
{
RangeString key = Lexer.GetNextTokenByType(TokenType.String);
Lexer.GetNextTokenByType(TokenType.Colon);
TokenType nextTokenType = Lexer.LookNextTokenType();
action(userdata1,userdata2,isIntKey,key, nextTokenType);
if (Lexer.LookNextTokenType() == TokenType.Comma)
{
Lexer.GetNextTokenByType(TokenType.Comma);
if (Lexer.LookNextTokenType() == TokenType.RightBracket)
{
throw new Exception("Json对象不能以逗号结尾");
}
}
else
{
break;
}
}
Lexer.GetNextTokenByType(TokenType.RightBrace);
}
|
这整个流程所做的就是将被一对大括号{}所包裹的N个Json键值对识别出来,然后将其传递到回调Action中
解析流程方法的参数中的回调Action一般以匿名方法的形式传入,为了优化匿名方法的内存消耗,额外设置了userdata1、userdata2、isIntKey这3个参数,具体可参看C#委托与匿名方法内存分配总结中的3.5优化建议一节
其使用方法以解析Json对象为字典为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
private static object ParseJsonObjectByDict(Type dictType, Type valueType)
{
IDictionary dict = (IDictionary)Activator.CreateInstance(dictType);
Type keyType = dictType.GetGenericArguments()[0];
ParseJsonObjectProcedure(dict, valueType,keyType == typeof(int), (userdata1, userdata2,isIntKey, key, nextTokenType) => {
Type t = (Type)userdata2;
object value = ParseJsonValueByType(nextTokenType, t);
if (!isIntKey)
{
((IDictionary)userdata1).Add(key.ToString(), value);
}
else
{
((IDictionary)userdata1).Add(int.Parse(key.ToString()), value);
}
});
return dict;
}
|
在得到key和value的tokenType后,将value解析出来,然后将key和value设置到字典实例中,最后完成整个字典的解析
解析Json数组的流程
解析Json数组的通用流程方法代码与解析Json对象的类似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public static void ParseJsonArrayProcedure(object userdata1,object userdata2, Action<object,object,TokenType> action)
{
Lexer.GetNextTokenByType(TokenType.LeftBracket);
while (Lexer.LookNextTokenType() != TokenType.RightBracket)
{
TokenType nextTokenType = Lexer.LookNextTokenType();
action(userdata1,userdata2,nextTokenType);
if (Lexer.LookNextTokenType() == TokenType.Comma)
{
Lexer.GetNextTokenByType(TokenType.Comma);
if (Lexer.LookNextTokenType() == TokenType.RightBracket)
{
throw new Exception("数组不能以逗号结尾");
}
}
else
{
break;
}
}
Lexer.GetNextTokenByType(TokenType.RightBracket);
}
|
用法以解析数组/List为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
private static object ParseJsonArrayByType(Type arrayType,Type elementType)
{
IList list;
if (arrayType.IsArray)
{
list = new List<object>();
}
else
{
list = (IList)Activator.CreateInstance(arrayType);
}
ParseJsonArrayProcedure(list, elementType, (userdata1, userdata2, nextTokenType) =>
{
object value = ParseJsonValueByType(nextTokenType, (Type)userdata2);
((IList)userdata1).Add(value);
});
if (!arrayType.IsArray)
{
return list;
}
Array array = Array.CreateInstance(elementType, list.Count);
for (int i = 0; i < list.Count; i++)
{
object element = list[i];
array.SetValue(element, i);
}
return array;
}
|
得到value的tokenType后将其解析出来,然后放入到一个List中,完成数组/List的解析
序列化与反序列化
在准备好通用解析流程方法后便可以开始着手于Json的序列化与反序列化工作
通用Json对象的序列化与反序列化
反序列化
首先定义Json值的类型枚举ValueType:
1
2
3
4
5
6
7
8
9
10
11
12
|
public enum ValueType
{
Null,
Boolean,
Number,
String,
Array,
Object,
}
|
Json值的类型只包含有null,bool,数字,字符串,数组和对象这几种
定义JsonValue来统一存放这几种Json数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class JsonValue
{
public ValueType Type;
public bool Boolean;
public double Number;
public string Str;
public JsonValue[] Array;
public JsonObject Obj;
}
|
定义JsonObject来提供一个可以通过索引器来访问键值对的Json通用对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class JsonObject
{
private Dictionary<string, JsonValue> valueDict;
public JsonValue this[string key]
{
get
{
if (valueDict == null)
{
return null;
}
return valueDict[key];
}
set
{
if (valueDict == null)
{
valueDict = new Dictionary<string, JsonValue>();
}
valueDict[key] = value;
}
}
}
|
对于通用Json对象的序列化与反序列而言,处理是非常简单的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private static JsonObject ParseJsonObject()
{
JsonObject obj = new JsonObject();
ParseJsonObjectProcedure(obj, null,false, (userdata1, userdata2,isIntKey, key, nextTokenType) => {
JsonValue value = ParseJsonValue(nextTokenType);
JsonObject jo = (JsonObject)userdata1;
jo[key.ToString()] = value;
});
return obj;
}
|
重点在于如何解析Json值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public static JsonValue ParseJsonValue(TokenType nextTokenType)
{
JsonValue value = new JsonValue();
switch (nextTokenType)
{
case TokenType.Null:
Lexer.GetNextToken(out _);
value.Type = ValueType.Null;
break;
case TokenType.True:
Lexer.GetNextToken(out _);
value.Type = ValueType.Boolean;
value.Boolean = true;
break;
case TokenType.False:
Lexer.GetNextToken(out _);
value.Type = ValueType.Boolean;
value.Boolean = false;
break;
case TokenType.Number:
RangeString token = Lexer.GetNextToken(out _);
value.Type = ValueType.Number;
value.Number = double.Parse(token.ToString());
break;
case TokenType.String:
token = Lexer.GetNextToken(out _);
value.Type = ValueType.String;
value.Str = token.ToString();
break;
case TokenType.LeftBracket:
value.Type = ValueType.Array;
value.Array = ParseJsonArray();
break;
case TokenType.LeftBrace:
value.Type = ValueType.Object;
value.Obj = ParseJsonObject();
break;
default:
throw new Exception("JsonValue解析失败,tokenType == " + nextTokenType);
}
return value;
}
|
只需要根据value的tokenType进行对应解析处理即可
序列化
通用Json对象的序列化只需要在JsonObject和JsonValue上定义好ToJson方法即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public class JsonObject
{
public void ToJson(int depth)
{
Util.AppendLine("{");
if (valueDict != null)
{
int index = 0;
foreach (KeyValuePair<string, JsonValue> item in valueDict)
{
Util.Append("\"", depth + 1);
Util.Append(item.Key);
Util.Append("\"");
Util.Append(":");
item.Value.ToJson(depth + 1);
if (index<valueDict.Count-1)
{
Util.AppendLine(",");
}
index++;
}
}
Util.Append("}", depth);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
public class JsonValue
{
public void ToJson(int depth)
{
switch (Type)
{
case ValueType.Null:
Util.Append("null");
break;
case ValueType.Boolean:
if (Boolean == true)
{
Util.Append("true");
}
else
{
Util.Append("false");
}
break;
case ValueType.Number:
Util.Append(Number.ToString());
break;
case ValueType.String:
Util.Append("\"");
Util.Append(Str);
Util.Append("\"");
break;
case ValueType.Array:
Util.AppendLine("[");
for (int i = 0; i < Array.Length; i++)
{
Util.AppendTab(depth + 1);
JsonValue jv = Array[i];
jv.ToJson(depth + 1);
if (i<Array.Length-1)
{
Util.AppendLine(",");
}
}
Util.AppendLine(string.Empty);
Util.Append("]",depth);
break;
case ValueType.Object:
Obj.ToJson(depth);
break;
default:
break;
}
}
}
|
自定义数据对象的序列化与反序列化
对于自定义数据对象,CatJson提供了2种方式进行序列化与反序列化:
- 基于反射
- 基于预生成代码
基于反射
基于反射的实现是大部分Json库的实现思路
反序列化
反序列化的实现在于通过反射获取到自定义类型的字段/属性的类型信息,然后再通过这个字段/属性的类型信息去解析出对应的Json值数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public static object ParseJsonObjectByType(Type type)
{
object obj = CreateInstance(type);
if (!propertyInfoDict.ContainsKey(type) && !fieldInfoDict.ContainsKey(type))
{
AddToReflectionMap(type);
}
ParseJsonObjectProcedure(obj, type,false, (userdata1, userdata2,isIntKey, key, nextTokenType) => {
Type t = (Type)userdata2;
propertyInfoDict.TryGetValue(t, out Dictionary<RangeString, PropertyInfo> dict1);
if (dict1 != null && dict1.TryGetValue(key, out PropertyInfo pi))
{
object value = ParseJsonValueByType(nextTokenType, pi.PropertyType);
pi.SetValue(userdata1, value);
}
else
{
fieldInfoDict.TryGetValue(t, out Dictionary<RangeString, FieldInfo> dict2);
if (dict2 != null && dict2.TryGetValue(key, out FieldInfo fi))
{
object value = ParseJsonValueByType(nextTokenType, fi.FieldType);
fi.SetValue(userdata1, value);
}
else
{
ParseJsonValue(nextTokenType);
}
}
});
return obj;
}
|
在解析Json值上与通用Json对象的解析过程大同小异:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
public static object ParseJsonValueByType(TokenType nextTokenType, Type type)
{
Type realType = CheckType(type);
switch (nextTokenType)
{
case TokenType.Null:
Lexer.GetNextToken(out _);
if (!realType.IsValueType)
{
return null;
}
break;
case TokenType.True:
case TokenType.False:
Lexer.GetNextToken(out _);
if (realType == typeof(bool))
{
return nextTokenType == TokenType.True;
}
break;
case TokenType.Number:
RangeString token = Lexer.GetNextToken(out _);
string str = token.ToString();
if (realType == typeof(byte))
{
return byte.Parse(str);
}
if (realType == typeof(int))
{
return int.Parse(str);
}
break;
case TokenType.String:
token = Lexer.GetNextToken(out _);
if (realType == typeof(string))
{
return token.ToString();
}
if (realType == typeof(char))
{
return char.Parse(token.ToString());
}
break;
case TokenType.LeftBracket:
if (Util.IsArrayOrListType(type))
{
Type elementType;
return ParseJsonArrayByType(type,elementType);
}
break;
case TokenType.LeftBrace:
if (Util.IsDictionaryType(type))
{
Type valueType;
return ParseJsonObjectByDict(type, valueType);
}
return ParseJsonObjectByType(type);
}
throw new Exception("ParseJsonValueByType调用失败,tokenType == " + nextTokenType + ",type == " + type.FullName);
}
|
RangeString优化
一般而言,在进行JsonKey与字段/属性名对比时,会调用Lexer通过字符串切割的形式将JsonKey提取出来,但是这会造成额外的内存消耗,为了优化这一点,笔者定义了一个表示范围字符串的结构体RangeString:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
public struct RangeString : IEquatable<RangeString>
{
private string source;
private int startIndex;
private int endIndex;
private int hashCode;
public RangeString(string source) : this(source,0,source.Length - 1)
{
}
public RangeString(string source, int startIndex, int endIndex)
{
this.source = source;
this.startIndex = startIndex;
this.endIndex = endIndex;
hashCode = 0;
}
public bool Equals(RangeString other)
{
bool isSourceNullOrEmpty = string.IsNullOrEmpty(source);
bool isOtherNullOrEmpty = string.IsNullOrEmpty(other.source);
if (isSourceNullOrEmpty && isOtherNullOrEmpty)
{
return true;
}
if (isSourceNullOrEmpty || isOtherNullOrEmpty)
{
return false;
}
int length = endIndex - startIndex + 1;
int otherLength = other.endIndex - other.startIndex + 1;
if (length != otherLength)
{
return false;
}
for (int i = startIndex, j = other.startIndex; i <= endIndex; i++, j++)
{
if (source[i] != other.source[j])
{
return false;
}
}
return true;
}
}
|
RangeString通过保存源字符串以及开始索引和结束索引,来表示在源字符串的一段范围内的字符所构成的字符串,主要作用在于避免通过字符串切割来进行字符串对比造成的内存开销
JsonLexer的提取Token方法会返回一个RangeString:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public RangeString GetNextToken(out TokenType type)
{
type = default;
switch (json[curIndex])
{
case 'n':
type = TokenType.Null;
ScanLiteral("null");
return default;
}
if (char.IsDigit(json[curIndex]) || json[curIndex] == '-')
{
string str = ScanNumber();
type = TokenType.Number;
return new RangeString(str);
}
if (json[curIndex] == '"')
{
RangeString rs = ScanString();
type = TokenType.String;
return rs;
}
throw new Exception("json解析失败,当前字符:" + json[curIndex]);
}
|
这样在进行JsonKey和字段/属性名的对比时,就会是RangeString和RangeString的对比,从而很大程度的避免掉字符串切割带来的额外内存开销
序列化
序列化过程同样是通过反射得到类型信息来进行整个序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
private static void AppendJsonObject(object obj, Type type, int depth)
{
if (!propertyInfoDict.ContainsKey(type) && !fieldInfoDict.ContainsKey(type))
{
AddToReflectionMap(type);
}
Util.AppendLine("{");
propertyInfoDict.TryGetValue(type, out Dictionary<RangeString, PropertyInfo> piDict);
if (piDict != null)
{
int index = 0;
foreach (KeyValuePair<RangeString, PropertyInfo> item in piDict)
{
object value = item.Value.GetValue(obj);
Type piType = item.Value.PropertyType;
string piName = item.Value.Name;
if (Util.IsDefaultValue(value))
{
continue;
}
AppendJsonKey(piName, depth+1);
AppendJsonValue(piType, value, depth+1);
if (index < piDict.Count-1)
{
Util.AppendLine(",");
}
index++;
}
}
fieldInfoDict.TryGetValue(type, out Dictionary<RangeString, FieldInfo> fiDict);
if (fiDict != null)
{
int index = 0;
foreach (KeyValuePair<RangeString, FieldInfo> item in fiDict)
{
object value = item.Value.GetValue(obj);
Type fiType = item.Value.FieldType;
string fiName = item.Value.Name;
if (Util.IsDefaultValue(value))
{
continue;
}
AppendJsonKey(fiName, depth+1);
AppendJsonValue(fiType, value, depth+1);
if (index < fiDict.Count-1)
{
Util.AppendLine(",");
}
index++;
}
}
Util.AppendLine(string.Empty);
Util.Append("}",depth);
}
|
重点在于对字段/属性值的序列化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
public static void AppendJsonValue(Type valueType, object value, int depth)
{
valueType = CheckType(valueType);
if (Util.IsNumber(value))
{
Util.Append(value.ToString());
return;
}
if (value is string || value is char)
{
Util.Append("\"");
Util.Append(value.ToString());
Util.Append("\"");
return;
}
if (value is bool)
{
bool b = (bool)value;
if (b == true)
{
Util.Append("true");
}
else
{
Util.Append("false");
}
return;
}
if (value is Enum)
{
int enumInt = (int)value;
Util.Append(enumInt.ToString());
return;
}
if (Util.IsArrayOrList(value))
{
AppendJsonArray(valueType, value, depth);
return;
}
if (Util.IsDictionary(value))
{
AppendJsonDict(value, depth);
return;
}
AppendJsonObject(value, valueType, depth);
}
|
基于预生成代码
通过预生成代码进行序列化与反序列化,相比基于反射,可以很好的降低CPU耗时以及值类型装箱的内存开销
其原理主要为通过编辑器下通过反射获取到类型的字符/属性信息,预生成好如同手工编写一般的代码
例如一个Json数据类定义如下:
1
2
3
4
5
6
7
8
9
10
11
| public class TestJson1_Root
{
public bool b;
public float num;
public string str;
public List<int> intList;
public Dictionary<string, int> intDict;
public TestJson1_Item item;
public List<TestJson1_Item> itemList;
public Dictionary<string, TestJson1_Item> itemDict;
}
|
其所生成的反序列化代码便是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| private static TestJson1_Root ParseJson_TestJson1_Root()
{
if (JsonParser.Lexer.LookNextTokenType() == TokenType.Null)
{
JsonParser.Lexer.GetNextToken(out _);
return null;
}
TestJson1_Root obj = new TestJson1_Root();
JsonParser.ParseJsonObjectProcedure(obj, null, false, (userdata1, userdata2, isIntKey, key, nextTokenType) =>
{
TestJson1_Root temp = (TestJson1_Root)userdata1;
TokenType tokenType;
if (key.Equals(new RangeString("b")))
{
JsonParser.Lexer.GetNextToken(out tokenType);
temp.b = tokenType == TokenType.True;
}
else if (key.Equals(new RangeString("num")))
{
temp.num = System.Single.Parse(JsonParser.Lexer.GetNextToken(out tokenType).ToString());
}
else if (key.Equals(new RangeString("str")))
{
temp.str = JsonParser.Lexer.GetNextToken(out tokenType).ToString();
}
else if (key.Equals(new RangeString("intList")))
{
List<System.Int32> list = new List<System.Int32>();
JsonParser.ParseJsonArrayProcedure(list, null, (userdata11, userdata21, nextTokenType1) =>
{
((List<System.Int32>)userdata11).Add(System.Int32.Parse(JsonParser.Lexer.GetNextToken(out tokenType).ToString()));
});
temp.intList = list;
}
else if (key.Equals(new RangeString("intDict")))
{
Dictionary<System.String, System.Int32> dict = new Dictionary<System.String, System.Int32>();
JsonParser.ParseJsonObjectProcedure(dict, null, false, (userdata11, userdata21, isIntKey1, key1, nextTokenType1) =>
{
((Dictionary<System.String, System.Int32>)userdata11).Add(key1.ToString(), System.Int32.Parse(JsonParser.Lexer.GetNextToken(out _).ToString()));
});
temp.intDict = dict;
}
else if (key.Equals(new RangeString("item")))
{
temp.item = ParseJson_TestJson1_Item();
}
else if (key.Equals(new RangeString("itemList")))
{
List<TestJson1_Item> list = new List<TestJson1_Item>();
JsonParser.ParseJsonArrayProcedure(list, null, (userdata11, userdata21, nextTokenType1) =>
{
if (nextTokenType1 == TokenType.Null)
{
JsonParser.Lexer.GetNextToken(out _);
((List<TestJson1_Item>)userdata11).Add(null);
return;
}
((List<TestJson1_Item>)userdata11).Add(ParseJson_TestJson1_Item());
});
temp.itemList = list;
}
else if (key.Equals(new RangeString("itemDict")))
{
Dictionary<System.String, TestJson1_Item> dict = new Dictionary<System.String, TestJson1_Item>();
JsonParser.ParseJsonObjectProcedure(dict, null, false, (userdata11, userdata21, isIntKey1, key1, nextTokenType1) =>
{
if (nextTokenType1 == TokenType.Null)
{
JsonParser.Lexer.GetNextToken(out _);
((Dictionary<System.String, TestJson1_Item>)userdata11).Add(key1.ToString(), null);
return;
}
((Dictionary<System.String, TestJson1_Item>)userdata11).Add(key1.ToString(), ParseJson_TestJson1_Item());
});
temp.itemDict = dict;
}
else
{
JsonParser.ParseJsonValue(nextTokenType);
}
});
return obj;
}
|
主要就是在通用解析流程回调中,通过if语句去匹配得到的JsonKey与字段/属性名,然后调用Lexer提取Value字符串出来,转换为对应的字段/属性类型并直接赋值,不会像基于反射的一样所有数据都作为object类型去操作